Günümüzde şirketler devamlı büyümek ve karar mekanizmalarını taze tutabilmek için düzenli veri akışına sahip olmalıdır. Neredeyse her şirket öyle ya da böyle bir şekilde veri toplar. İçerisinde bulunduğumuz Big Data ve AI döneminde, verilere dayalı öngörüler altın değerindedir. Ancak şirketlerin kullandıkları veritabanları, pipeline’lar ve otomasyon sistemleri belli bir noktaya kadar veri tekrarına sebep olabilmektedir.
Daha detaylı ve rafine veriler için daha gelişmiş data management yöntemlerine başvurmak gerekebilmektedir. Yani basit bir dil ile Data Normalization, verilerin daha kolay bulunabilmesi ve işlenebilmesi için kullanılan bir standartizasyon tekniklerinin tamamıdır. Data Normalization sayesinde verilerin analizi ve gruplandırılması da kolayaşır.
Data Normalization’un Önemi
Data Normalization, Data Pipeline’ınız içerisinde yer alabilir, ki öyle bir durumda gözlemlenebilirliğini destekler. Nihayi olarak da verinizin optimize edilmesinde kilit bir rol oynar ve bir veriden alabileceğiniz verimliliği de arttırır.
Bir çok kişi ve kuruluş için ne yazık ki data normalization zor bir hedef. Neden mi? Ellerindeki veriler devasa. Bu verilen bir kısmı işlevsiz olduğundan dolayı şirketler bu veriyi düzenlemeye çok uğraşmazlar. Ancak bulunduğumuz AI döneminde her verinin neredeyse öyle ya da böyle bir faydası dokunur.
Data Normalizing Nasıl Yapılır?
Daha önceden dediğimiz gibi Data Normalization aslında elimizdeki veriyi standartlaştırma prosedürüdür. Kullandığımız veriye göre standartlaştırmaya yaklaşmamız farklı olacaktır.
Örnek
- “Doktor Ali” yerine “Dr. Ali” kullanılabilir
- 998724412 yerine 998-724-412 kullanılabilir
- “Çiçek Sokak 1912 Numara” yerine “Sk:Cicek No:1912” kullanılabilir
Bunun gibi bir sürü örnek sıralayabiliriz. Normalizasyon sırasında oluşabilecek anomalilere karşı birden çok teknik geliştirilmiştir. Bunları şöyle sıralayabiliriz:
- First Normal Form (1NF)
- Second Noral Form (2NF)
- Third Normal Form (3NF)
- Boyce and Codd Normal Form (3.5 NF)
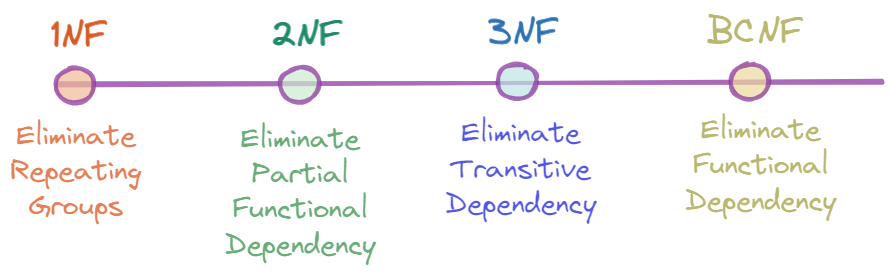
Data Normalization Teknikleri
1.First Normal Form (1NF)
Bu teknik aralarındaki en basit olanıdır. Sonuçların içerisinde veri tekrarı olmamasını amaçlayan tekniktir. Yani:
- Her kayıt kendine özgü (unique) olmalıdır.
- Her hücrenin içerisinde tek bir değer olmalıdır.
Örnek: Bir alışveriş sitesinde hesabındaki veriler: İsim, Adres, Cinsiyet gibi değerlerle belirtilmelidir.
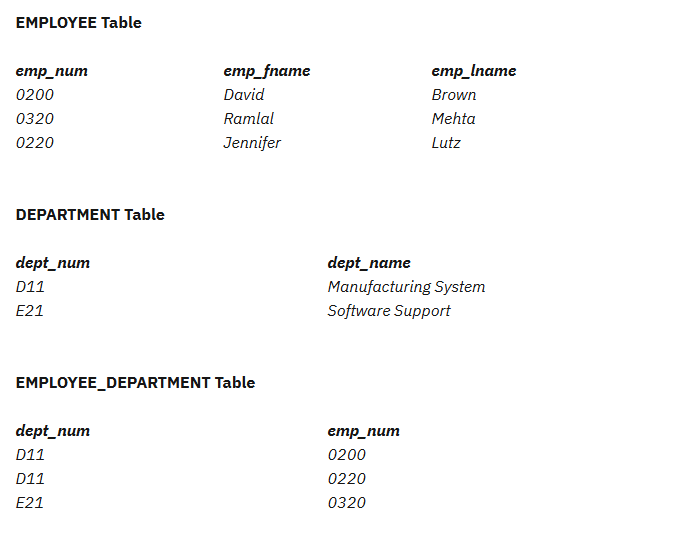
2. Second Normal Form (2NF)
2NF tekniği 1NF’nin temelinin üzerine koyarak ilerler. Bu tekniğe göre verisetinde veri tekrarını azaltabilmek için primary key kullanmak şarttır. Primary Key sayesinde elimizdeki veriyi birden fazla dataset’e bölüp, verilerden çok daha fazla veri alabiliriz.
Örnek:
| Customer Number | Name | Adres | Cinsiyet |
| 1 | Mehmet Ali | Mavi Sokak 34 Numara | E |
| 2 | Burcu Özsoy | Çiçek Sokak 12 Numara | K |
| Customer Number | Sipariş |
| 1 | T-Shirt |
| 1 | Gömlek |
| 2 | Bluz |
3. Third Normal Form (3NF)
Third Normal Form’da aynı şekilde 2NF’yi temelini üzerine koyarak devam eder. Bir kişinin adı, adresi ve cinsiyeti kaydediliyor olsun. Daha sonra adı değiştirdiğinizde, cinsiyetin de değişmesi gerekebiliyorsa, bu durumda cinsiyet doğrudan primary key’e bağlı değildir. Bu nedenle cinsiyet için bir yabancı anahtar (foreign key) tanımlanır ve cinsiyete ait tüm veriler ayrı bir tabloya yerleştirilir.
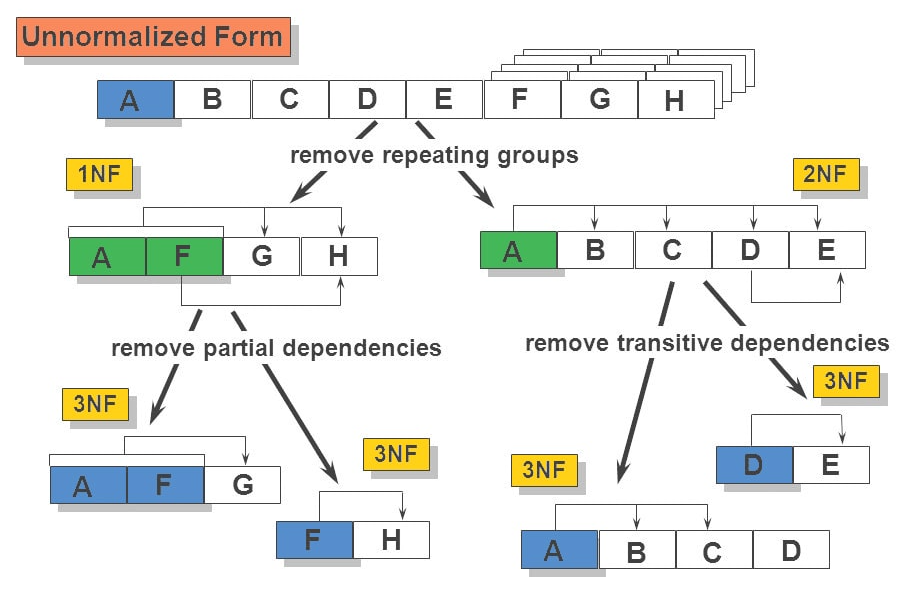
4. Boyce and Codd Normal Form (3.5 NF)
Boyce-Codd Normal Form (BCNF ya da 3.5NF olarak da bilinir), 3. normal form (3NF) veri modelinin geliştirilmiş bir versiyonudur. 3.5NF, aday anahtarların (candidate key) çakışmadığı bir 3NF tablosudur. Bu normal form şu kuralları içerir:
- 3NF’te olmalıdır.
- Her fonksiyonel bağımlılık (X → Y) için X bir süper anahtar (super key) olmalıdır.
Temel olarak bu şu anlama gelir: X → Y şeklindeki bir bağımlılıkta, eğer Y bir özel(prime) öznitelikse, X asal olmayan (non-prime) bir öznitelik olamaz.